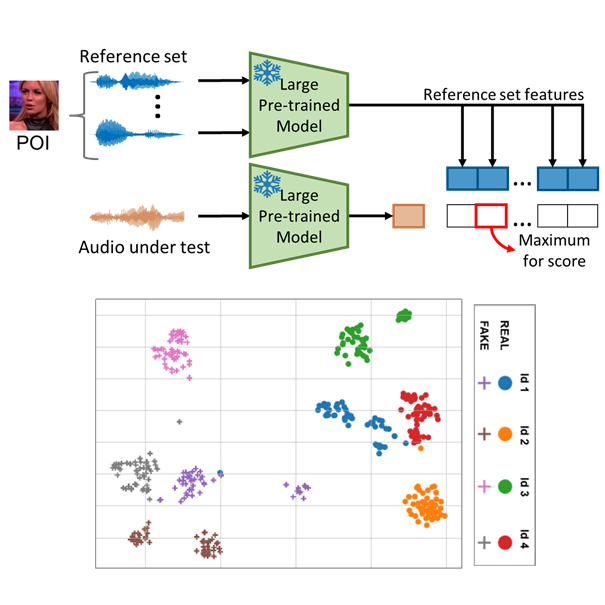
Generalization is a main issue for current audio deepfake detectors, which struggle to provide reliable results on out-of-distribution data. Given the speed at which more and more accurate synthesis methods are developed, it is very important to design techniques that work well also on data they were not trained for. In this paper we study the potential of large-scale pre-trained models for audio deepfake detection, with special focus on generalization ability. To this end, the detection problem is reformulated in a speaker verification framework and fake audios are exposed by the mismatch between the voice sample under test and the voice of the claimed identity. With this paradigm, no fake speech sample is necessary in training, cutting off any link with the generation method at the root, and ensuring full generalization ability. Features are extracted by general-purpose large pre-trained models, with no need for training or fine-tuning on specific fake detection or speaker verification datasets. At detection time only a limited set of voice fragments of the identity under test is required. Experiments on several datasets widespread in the community show that detectors based on pre-trained models achieve excellent performance and show strong generalization ability, rivaling supervised methods on in-distribution data and largely overcoming them on out-of-distribution data.
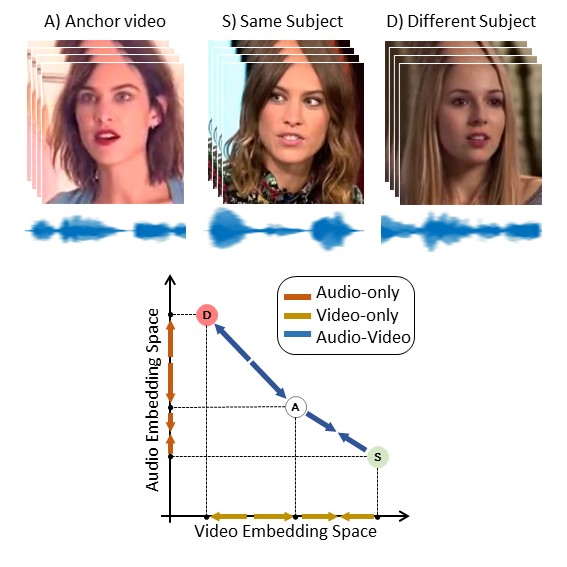
Face manipulation technology is advancing very rapidly, and new methods are being proposed day by day. The aim of this work is to propose a deepfake detector that can cope with the wide variety of manipulation methods and scenarios encountered in the real world. Our key insight is that each person has specific biometric characteristics that a synthetic generator cannot likely reproduce. Accordingly, we extract high-level audio-visual biometric features which characterize the identity of a person, and use them to create a person-of-interest (POI) deepfake detector. We leverage a contrastive learning paradigm to learn the moving-face and audio segments embeddings that are most discriminative for each identity. As a result, when the video and/or audio of a person is manipulated, its representation in the embedding space becomes inconsistent with the real identity, allowing reliable detection. Training is carried out exclusively on real talking-face videos, thus the detector does not depend on any specific manipulation method and yields the highest generalization ability. In addition, our method can detect both single-modality (audio-only, video-only) and multi-modality (audio-video) attacks, and is robust to low-quality or corrupted videos by building only on high-level semantic features. Experiments on a wide variety of datasets confirm that our method ensures a SOTA performance, with an average improvement in terms of AUC of around 3%, 10%, and 7% for high-quality, low quality and attacked videos, respectively.
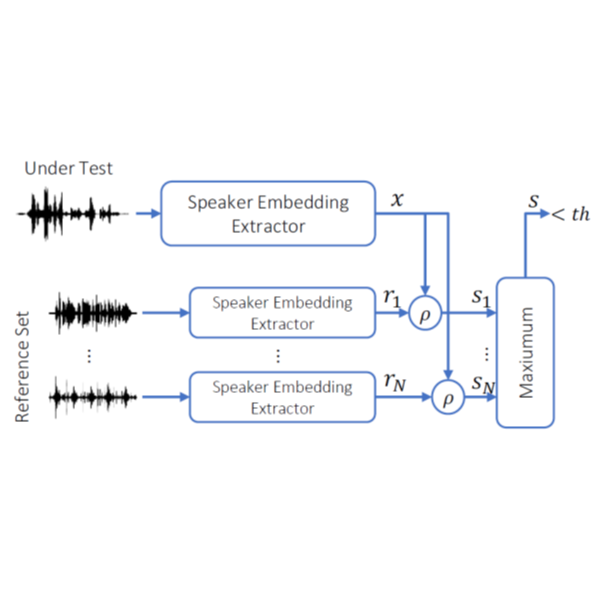
Thanks to recent advances in deep learning, sophisticated generation tools exist, nowadays, that produce extremely realistic synthetic speech. However, malicious uses of such tools are possible and likely, posing a serious threat to our society. Hence, synthetic voice detection has become a pressing research topic, and a large variety of detection methods have been recently proposed. Unfortunately, they hardly generalize to synthetic audios generated by tools never seen in the training phase, which makes them unfit to face real-world scenarios. In this work, we aim at overcoming this issue by proposing a new detection approach that leverages only the biometric characteristics of the speaker, with no reference to specific manipulations. Since the detector is trained only on real data, generalization is automatically ensured. The proposed approach can be implemented based on off-the-shelf speaker verification tools. We test several such solutions on three popular test sets, obtaining good performance, high generalization ability, and high robustness to audio impairment.
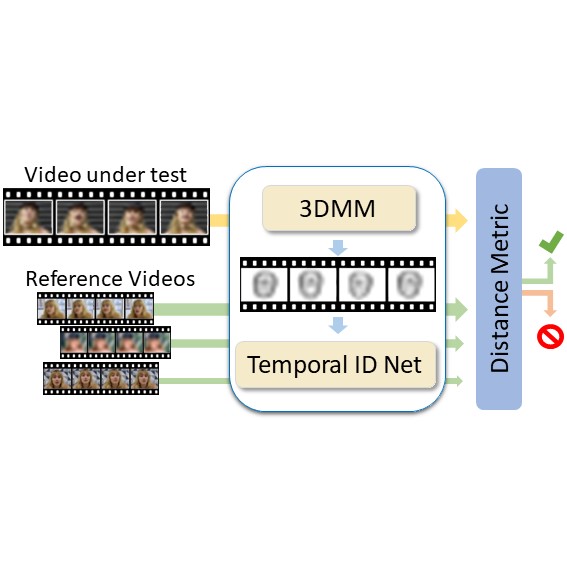
A major challenge in DeepFake forgery detection is that state-of-the-art algorithms are mostly trained to detect a specific fake method. As a result, these approaches show poor generalization across different types of facial manipulations, e.g., from face swapping to facial reenactment. To this end, we introduce ID-Reveal, a new approach that learns temporal facial features, specific of how a person moves while talking, by means of metric learning coupled with an adversarial training strategy. The advantage is that we do not need any training data of fakes, but only train on real videos. Moreover, we utilize high-level semantic features, which enables robustness to widespread and disruptive forms of post-processing. We perform a thorough experimental analysis on several publicly available benchmarks. Compared to state of the art, our method improves generalization and is more robust to low-quality videos, that are usually spread over social networks. In particular, we obtain an average improvement of more than 15% in terms of accuracy for facial reenactment on high compressed videos.
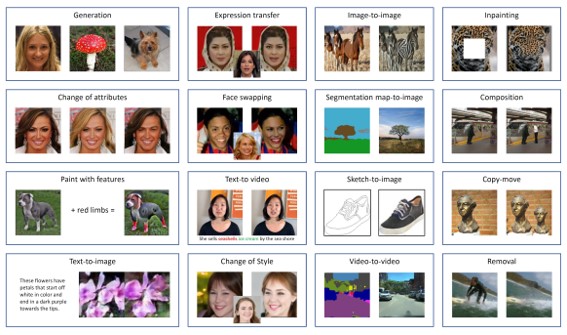
With the rapid progress of recent years, techniques that generate and manipulate multimedia content can now guarantee a very advanced level of realism. The boundary between real and synthetic media has become very thin. On the one hand, this opens the door to a series of exciting applications in different fields such as creative arts, advertising, film production, video games. On the other hand, it poses enormous security threats. Software packages freely available on the web allow any individual, without special skills, to create very realistic fake images and videos. So-called deepfakes can be used to manipulate public opinion during elections, commit fraud, discredit or blackmail people. Potential abuses are limited only by human imagination. Therefore, there is an urgent need for automated tools capable of detecting false multimedia content and avoiding the spread of dangerous false information. This review paper aims to present an analysis of the methods for visual media integrity verification, that is, the detection of manipulated images and videos. Special emphasis will be placed on the emerging phenomenon of deepfakes and, from the point of view of the forensic analyst, on modern data-driven forensic methods. The analysis will help to highlight the limits of current forensic tools, the most relevant issues, the upcoming challenges, and suggest future directions for research.

The rapid progress in synthetic image generation and manipulation has now come to a point where it raises significant concerns for the implications towards society. At best, this leads to a loss of trust in digital content, but could potentially cause further harm by spreading false information or fake news. This paper examines the realism of state-of-the-art image manipulations, and how difficult it is to detect them, either automatically or by humans. To standardize the evaluation of detection methods, we propose an automated benchmark for facial manipulation detection. In particular, the benchmark is based on DeepFakes, Face2Face, FaceSwap and NeuralTextures as prominent representatives for facial manipulations at random compression level and size. The benchmark is publicly available and contains a hidden test set as well as a database of over 1.8 million manipulated images. This dataset is over an order of magnitude larger than comparable, publicly available, forgery datasets. Based on this data, we performed a thorough analysis of data-driven forgery detectors. We show that the use of additional domainspecific knowledge improves forgery detection to unprecedented accuracy, even in the presence of strong compression, and clearly outperforms human observers.

Video source attribution is an important operation in forensics applications. Identifying which specific device or camera model took a video can help in authorship verification, but can be also a precious source of information for detecting a possible manipulation. The key observation is that any physical device leaves peculiar traces in the acquired content, a sort of fingerprint that can be exploited to establish data provenance. Moreover, absence or modification of such traces may reveal a possible manipulation. In this paper, inspired by recent work on images, we train a neural network that enhances the model-related traces hidden in a video, extracting a sort of camera fingerprint, called video noiseprint. The net is trained on pristine videos with a Siamese strategy, minimizing distances between same-model patches, and maximizing distances between unrelated patches. Experiments show that methods based on video noiseprints perform well in major forensic tasks, such as camera model identification and video forgery localization, with no need of prior knowledge on the specific manipulation or any form of fine-tuning.