Program
S3P2024 will take place in Anacapri (island of Capri) from 23-27 September 2024.
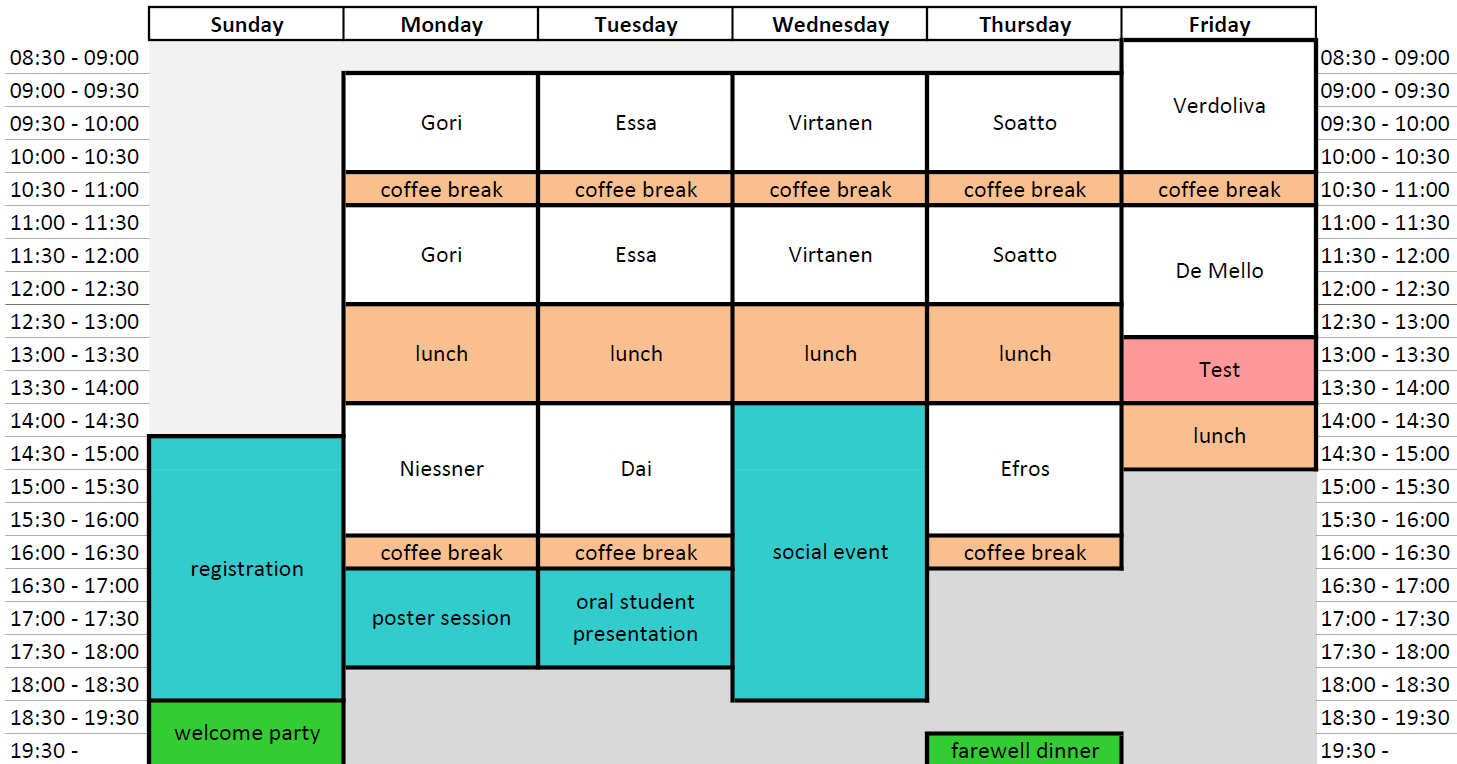
Monday 23
Marco Gori (University of Siena, Italy) Collectionless machine learning
Matthias Nießner (Technical University of Munich, Germany) Photo-realistic AI Avatars
Tuesday 24
Irfan Essa (Georgia Institute of Technology and Google, USA) Generative Video: New Models, Applications and Challenges
Angela Dai (Technical University of Munich, Germany) Learning to Understand the 3D World
Wednesday 25
Tuomas Virtanen (University of Tampere, Finland) Computational analysis of everyday acoustic scenes: methods, data, and evaluation
Thursday 26
Stefano Soatto (University of California Los Angeles, USA) Representation Learning for Concepts and Meanings: From Inductive Learning of Signals to Reasoning about the World
Alexei (Alyosha) Efros (University of California, Berkeley, USA) Algorithms vs Data: what's more important?
Friday 27
Tal Hassner (Meta, USA) Real Faces, Fake Faces: From AI to Responsible AI
Luisa Verdoliva (University Federico II of Napoli, Italy) Synthetic Media Verification in the Era of Generative AI
Shalini De Mello (NVIDIA Research, USA) AI-Mediated Reality: From Synthesis To Verification
Student Poster Session
- Luca Savant Aira: Modeling Uncertainty for Gaussian Splatting
- Chiara Albisani: Self-Supervised SAR Despeckling using Deep Image Prior (ORAL)
- Yaser Gholizade Atani: Subsequence-Based Interpretable Method for Time Series Classification
- Giulia Bertazzini: CoFFEE: A Codec-based Forensic Feature Extraction and Evaluation Software for H.264 Videos
- Costanza Cenerini: Towards Sensory Substitution
- Teodor Chiaburu: Uncertainty in XAI (ORAL)
- Federico Cocchi: Contrasting Deepfakes Diffusion via Contrastive Learning and Global-Local Similarities (ORAL)
- Lion Jasper Gleiter: A Human-in-the-loop Organoid Instance Segmentation and Tracking Pipeline for Lensless Microscopy Videos (ORAL)
- Nasrin Malekzadeh Goradel: Existence of Adversarial Examples on Riemannian Manifolds
- Maximilian Hörmann: Cell Detection and Label-Free Cell Death Prediction on Lensless Microscopy Images
- Ivan Kondyurin: Modelling Social Intentions in Complex Conversational Settings (ORAL)
- Weiwei Liu: Retraining a Multimodal Transformer to Digitize Herbarium Specimen Labels with an End-to-end Solution
- Federica Massimi: Design and Development of ML and DL Algorithms and Techniques for the Identification and Classification of Spatial Targets through the Processing of Radar Signals
- Saleemullah Memon: LiDAR based Blockage Prediction in Integrated Sensing & Communication for Intelligent Transportation Systems
- Thomas De Min: Less is more: Summarizing Patch Tokens for efficient Multi-Label Class-Incremental Learning (ORAL)
- Mujtaba Hussain Mirza: Shedding More Light on Robust Classifiers under the Lens of Energy-Based Models (ORAL)
- Batuhan Ozcomlekci: CloSe: A 3D Clothing Segmentation Dataset and Model
- Giulia Rizzoli: When Cars meet Drones: Hyperbolic Federated Learning for Source-Free Domain Adaptation in Adverse Weather (ORAL)
- Erica Rocchi: On the Design of a Framework for QoE Assessment For XR Applications
- Antonio Luigi Stefani: Towards Multimodal VR: Integrating Haptic Surface Modelling with 3D Scenes
- Claudia Melis Tonti: Lightweight 3-D Convolutional Occupancy Networks for Virtual Object Reconstruction
